

What is Vector Index?
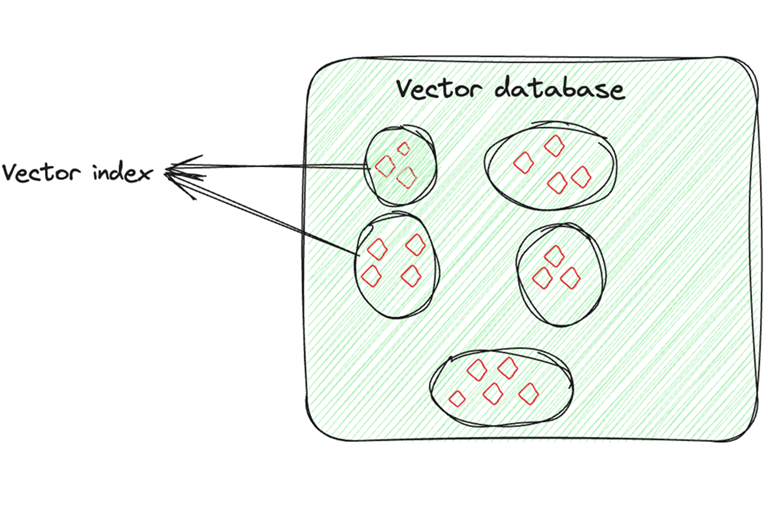
A vector index is a data structure designed to efficiently store, organize, and search vector embeddings (numerical representations) of data. These embeddings are commonly used to represent data such as text, images, audio, or any other unstructured data that has been transformed into a vector through a process known as embedding. The vector index facilitates fast similarity searches, where data that is similar or close to a given query vector can be retrieved quickly based on specific metrics (such as cosine similarity or Euclidean distance). What is Vector Index? In this article, we will explore the role of vector indexes in enabling efficient data retrieval and how they enhance the performance of machine learning and AI applications.
How Does a Vector Index Work?
The core function of a vector index is to optimize search operations, enabling a system to compare a query vector with a large number of vectors in the database efficiently.
1. Vector Storage
The vector index stores all vectors generated from the data in a structured format. Each vector represents a data point (e.g., a document, image, or product) in a high-dimensional space, often generated by machine learning models such as BERT (for text) or CNNs (for images).
2. Search Optimization
When a user submits a query, it is transformed into a vector using the same model as the stored vectors. The vector index is then used to compare the query vector with those in the database. The index helps identify the vectors closest to the query vector based on the selected similarity metric.
3. Similarity Measures
The index employs various mathematical measures such as cosine similarity, Euclidean distance, or dot product to calculate the similarity between vectors. The goal is to find vectors that are closest to the query vector in vector space, indicating that the corresponding data is relevant to the user’s search.
4. Efficient Searching
A well-designed vector index reduces the number of comparisons needed between the query vector and the stored vectors, optimizing search performance. High-dimensional spaces can be slow and computationally expensive, so specialized indexing structures are utilized to speed up the search process.
Types of Vector Indexing Techniques
1. Flat (Brute Force) Index
This simple approach compares every vector in the database to the query vector to calculate similarity.
- Pros: Easy to implement and guarantees exact results.
- Cons: Slow and computationally expensive, especially with large datasets, as it requires comparing each vector in the database.
2. Tree-Based Indexing
These methods partition the vector space hierarchically using data structures like KD-Trees or Ball Trees. The space is divided into smaller regions or clusters, allowing the search to focus on relevant areas.
- Pros: Faster than brute-force search for low-dimensional spaces.
- Cons: Efficiency decreases with high-dimensional data due to the "curse of dimensionality," where the volume of the vector space grows exponentially.
3. Approximate Nearest Neighbor (ANN) Search
ANN search techniques such as HNSW (Hierarchical Navigable Small World), FAISS (Facebook AI Similarity Search), and Annoy are designed to speed up vector search by approximating the nearest neighbors instead of finding exact matches.
- Pros: Fast and scalable, especially for high-dimensional data, with acceptable accuracy.
- Cons: Results may not always be exact but are typically close enough for most applications.
4. LSH (Locality-Sensitive Hashing)
LSH is used for dimensionality reduction, hashing similar vectors into the same "bucket" or group. Hash functions ensure that similar items are more likely to collide in the same bucket, enabling efficient retrieval.
- Pros: Excellent for high-dimensional data and large-scale datasets.
- Cons: May introduce approximation, leading to lower accuracy.
5. Product Quantization
Product quantization compresses vectors into smaller codes, reducing the search complexity. It divides the vector space into subspaces and quantizes each independently, making comparisons more efficient.
- Pros: Reduces storage requirements and is great for large datasets.
- Cons: Can introduce some error in the search results.
Applications of Vector Index
1. Semantic Search
Vector indexes enable semantic search, finding results based on meaning rather than exact keyword matches. For instance, a search for "best smartphones 2025" can return results about upcoming phones even if the exact words aren’t in the document.
2. Recommendation Systems
In recommendation engines, vector indexes store embeddings of user preferences and products. The system can quickly recommend items that are similar to a user’s past preferences based on the similarity of vectors.
3. Image Retrieval
In image search, vector indexes are used to find visually similar images to a given query. When an image is uploaded, it is converted into a vector, and the index retrieves the most similar images.
4. Audio Matching
For audio search, vector indexes store embeddings of audio features, allowing efficient searching and matching of similar audio clips such as speech or music.
5. Document Classification and Clustering
In NLP tasks like document classification or clustering, vector indexes enable the system to quickly compare and categorize documents based on their vector embeddings.
Benefits of a Vector Index
- Speed and Efficiency: A well-optimized vector index enables fast similarity searches, even with large datasets, making it ideal for real-time applications like recommendation systems and search engines.
- Scalability: Vector indexes handle massive datasets efficiently, enabling search and retrieval in high-dimensional spaces.
- Accuracy: By using similarity measures and approximate search techniques, vector indexes can find highly relevant results, even when exact matches don’t exist, making them more flexible than traditional keyword-based systems.
- Dimensionality Reduction: Techniques like ANN and LSH help reduce the complexity of high-dimensional data, ensuring fast searches with minimal accuracy loss.
Challenges of Vector Indexing
- High Dimensionality: As vector dimensions increase, search and indexing can slow down due to the "curse of dimensionality." This makes indexing high-dimensional data difficult.
- Storage Requirements: Storing vectors and their indexes can take up significant space, especially for large datasets. Compression techniques like product quantization are often needed to manage storage.
- Accuracy vs. Speed Trade-off: There is always a balance between accuracy and speed. Approximate methods like ANN may offer faster searches but less precise results, while brute-force searches provide exact results at the cost of speed.
Conclusion
A vector index is essential for fast, efficient, and scalable similarity searches across high-dimensional data. By organizing and storing vector embeddings in an optimized way, vector indexes enable applications like semantic search, recommendation systems, and image retrieval to quickly find relevant data. As AI and machine learning technologies continue to evolve, the role of vector indexes will expand, helping businesses extract more value from their data and delivering faster, more relevant results.
At Flax Infotech, we implement cutting-edge vector indexing solutions to help businesses leverage advanced search capabilities and make smarter, more efficient decisions.
