

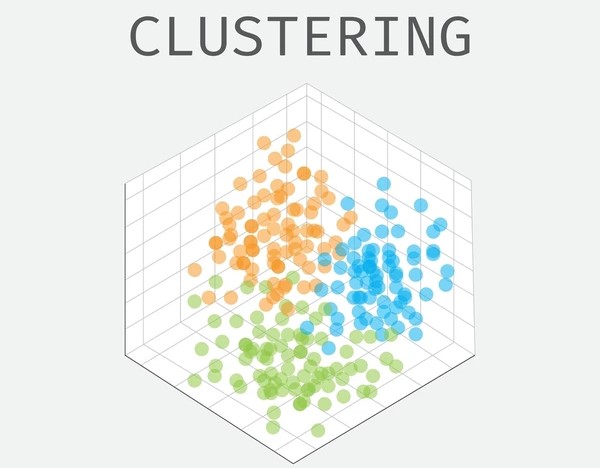
What is Vector Space Clustering?
Vector Space Clustering is a technique used to group a set of objects or data points (such as documents, images, or any other form of data) based on their similarity in a multi-dimensional vector space. The main idea is to represent each data point as a vector in a high-dimensional space and then apply clustering algorithms to partition the data into meaningful groups or clusters based on how similar the data points are to each other. What is Vector Space Clustering? In this article, we will explore the concept of Vector Space Clustering, its methods, and how it is used to analyze complex data sets by grouping similar data points together.
The technique is commonly applied to text clustering, where documents are represented as vectors in a vector space model (such as TF-IDF or word embeddings), and then clustering algorithms like K-means or hierarchical clustering are used to group similar documents together. However, vector space clustering can be applied to any type of data that can be represented as vectors.
How Does Vector Space Clustering Work?
Vector Space Clustering works in the following steps:
1. Data Representation
In vector space clustering, each data point (e.g., a document, image, or user profile) is converted into a vector representation. For text-based applications, each term in the dataset (such as words in documents) is mapped to a dimension, and the value of each dimension typically represents the frequency or weight of the term in the document.
For example, in text clustering, the TF-IDF (Term Frequency-Inverse Document Frequency) model is commonly used to convert text into vectors. Alternatively, word embeddings (such as Word2Vec or GloVe) can be used to represent text in dense, lower-dimensional vectors that capture semantic meanings of words.
2. Clustering Algorithm Selection
Once the data points are represented as vectors, a clustering algorithm is applied to group them into clusters. Common algorithms include:
- K-means Clustering: This algorithm partitions the data into a predefined number of clusters (K) by iteratively assigning data points to the nearest centroid and adjusting the centroids until convergence.
- Hierarchical Clustering: This approach builds a tree of clusters (dendrogram) by successively merging or splitting clusters based on their similarity.
- DBSCAN: This algorithm groups data points that are closely packed together and marks points in low-density regions as outliers.
- Gaussian Mixture Models (GMM): This probabilistic model assumes that the data points are generated from a mixture of several Gaussian distributions and estimates the parameters of these distributions.
3. Similarity Calculation
To determine how similar the data points are to each other, various similarity or distance metrics are used. The most common similarity measures include:
- Cosine Similarity: Measures the cosine of the angle between two vectors, commonly used for text data.
- Euclidean Distance: Measures the straight-line distance between two vectors, often used in K-means clustering.
- Manhattan Distance: The sum of the absolute differences of the coordinates of the vectors.
- Jaccard Similarity: Measures similarity between two sets by dividing the intersection of the sets by their union, useful for categorical data.
4. Cluster Formation
Once the similarity between vectors is calculated, the algorithm assigns each data point to a cluster based on its proximity to other data points. The clustering algorithm iterates over the data, refining the clusters until an optimal grouping is achieved.
Key Types of Vector Space Clustering
- Document Clustering: Clustering text documents based on content, useful for topic modeling and content organization.
- Image Clustering: Grouping images based on similarity in features like pixel values or embeddings from CNNs.
- User Behavior Clustering: Segmenting users based on browsing behavior, purchasing history, or preferences.
- Gene Clustering in Bioinformatics: Grouping genes based on similar expression patterns for biological research.
Advantages of Vector Space Clustering
- Automated Grouping: It enables automatic categorization of large datasets without needing predefined labels.
- Scalability: It can handle large datasets efficiently, especially with algorithms like K-means or DBSCAN.
- Discovery of Hidden Patterns: It helps uncover natural groupings in data that were previously unknown.
- Improved Information Retrieval: It enhances recommendation systems by grouping similar documents or items together.
Challenges of Vector Space Clustering
- Choosing the Right Number of Clusters: Some algorithms, like K-means, require the number of clusters to be predefined, which can be difficult without prior knowledge of the data.
- High Dimensionality: High-dimensional vector spaces can lead to sparsity and computational inefficiency.
- Cluster Interpretability: The resulting clusters might not always be easy to interpret.
- Sensitivity to Initial Conditions: Some algorithms are sensitive to initial conditions, leading to different results based on initialization.
Enhancements to Vector Space Clustering
- Dimensionality Reduction: Techniques like PCA or t-SNE help reduce the dimensionality of the data, improving efficiency.
- Advanced Clustering Algorithms: Algorithms like GMM or DBSCAN can handle complex data distributions and noise more effectively.
- Deep Learning-Based Clustering: Techniques such as autoencoders and self-organizing maps (SOMs) are being used for clustering high-dimensional data.
Applications of Vector Space Clustering
- Search Engine Optimization: Grouping web pages or documents for more relevant search results.
- Social Media Analytics: Detecting communities or identifying trending topics through user behavior clustering.
- Market Research: Segmenting customers based on preferences for targeted marketing.
- Bioinformatics: Identifying gene clusters related to specific biological processes or diseases.
