

What is Vector Space Query?
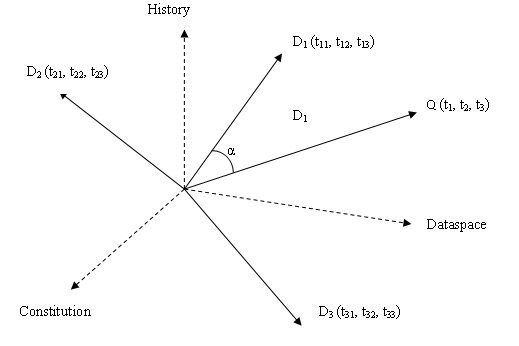
A Vector Space Query refers to a search query that is represented as a vector in the Vector Space Model (VSM), a mathematical framework widely used in Information Retrieval (IR) and Natural Language Processing (NLP). In this model, both documents and queries are transformed into vectors within a multi-dimensional space, where each dimension represents a unique term or keyword from the collection of documents. The Vector Space Query allows for comparing search queries with documents in a database, aiming to retrieve and rank the most relevant documents by evaluating the similarity between the query vector and document vectors. What is Vector Space Query? In this article, we will explore how Vector Space Queries work, their role in information retrieval, and how they improve search accuracy and relevancy in large data sets.
How Does a Vector Space Query Work?
The process of using a Vector Space Query works in the following steps:
1. Query Representation
When a user submits a search query, it is converted into a vector. Each word in the query becomes a term in the vector space, and its importance is often weighted using Term Frequency-Inverse Document Frequency (TF-IDF) or similar techniques.
- Term Frequency (TF): Measures the number of times a term appears in the query.
- Inverse Document Frequency (IDF): Measures how rare or common a term is in the entire corpus of documents.
2. Document Representation
Similarly, each document in the collection is represented as a vector in the same multi-dimensional space, with each term’s frequency or weight determining its value in the vector.
3. Similarity Calculation
After both the query and documents are represented as vectors, the system compares the query vector with each document’s vector using similarity measures such as:
- Cosine Similarity: Calculates the cosine of the angle between two vectors. The closer the angle is to zero, the more similar the two vectors are.
- Euclidean Distance: Measures the straight-line distance between the query vector and the document vectors. The smaller the distance, the more similar the document is to the query.
4. Ranking and Retrieval
Once the similarity between the query and documents is calculated, the documents are ranked in order of relevance. The documents most similar to the query vector appear first in the search results.
Example of a Vector Space Query
Consider a small example where a user wants to search for documents related to “artificial intelligence.” The system has a collection of documents, and the query is represented as a vector, for example:
[0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 1]
Where the terms in the vector correspond to words in the document corpus, such as "artificial," "intelligence," "machine," "learning," etc. The values in the vector represent the importance or frequency of those terms in the query.
Suppose the system compares this query vector to the vectors representing the documents. Each document’s vector might look like this:
[0, 1, 0, 0, 1, 0, 0, 0, 0, 0, 1] (Document 1)
[1, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0] (Document 2)
The system then calculates the cosine similarity or Euclidean distance between the query vector and each document vector. The documents most similar to the query vector will be ranked higher in the search results.
Advantages of Using Vector Space Queries
Vector space queries provide several key benefits:
- Relevance Ranking: It allows for more refined and accurate ranking of documents based on similarity, improving the relevance of search results.
- Flexibility: Vector space queries are flexible in handling synonyms and related terms, as the system can compare documents even if the exact wording differs in the query.
- Precision and Recall: By using similarity measures like cosine similarity, the system can balance precision (relevance of top documents) and recall (wide coverage of relevant documents).
Challenges of Vector Space Queries
Despite its advantages, there are some challenges with vector space queries:
- High Dimensionality: As the vocabulary of terms grows, the vector space becomes high-dimensional, leading to inefficiencies in storage, computation, and performance.
- Sparsity: Many document vectors are sparse (contain many zero values), which can lead to challenges when processing large datasets efficiently.
- Lack of Semantic Understanding: Basic vector space queries rely on word matching and frequency, without capturing deeper meanings or context. For instance, "AI" and "artificial intelligence" may not be recognized as conceptually similar.
Enhancements to Vector Space Queries
Several techniques can improve vector space queries:
1. Latent Semantic Analysis (LSA)
LSA reduces the dimensionality of the vector space and uncovers hidden relationships between terms, improving the handling of synonyms and related terms.
2. Word Embeddings
Techniques like Word2Vec, GloVe, and FastText map words into dense vectors that capture their semantic meanings, improving query results by better understanding the context of words.
3. Machine Learning
Machine learning models can refine query relevance over time, improving search results based on user interactions and feedback.
Applications of Vector Space Queries
Vector space queries are applied in various fields:
1. Search Engines
Google, Bing, and other search engines use vector space queries to match user queries with documents and rank them based on relevance.
2. Recommendation Systems
E-commerce platforms use vector space queries to recommend products based on user searches and past preferences.
3. Chatbots and Virtual Assistants
Chatbots use vector space queries to match user queries with appropriate responses from a database of pre-defined answers or knowledge.
4. Document Classification
Vector space queries are used in text classification tasks, where queries or documents are classified into predefined categories.
Conclusion
A Vector Space Query is an essential component of the Vector Space Model in Information Retrieval. By representing queries and documents as vectors and comparing their similarity, the system can rank documents effectively based on relevance. While the Vector Space Model is flexible and scalable, advancements in techniques like Latent Semantic Analysis and word embeddings continue to enhance query intent and document relevance. These innovations make it an invaluable tool in the development of search engines, recommendation systems, and NLP applications.
Contact Flax Infotech today to explore how advanced Vector Space Query techniques and the latest NLP technologies can help your business optimize search, enhance recommendations, and deliver smarter, more accurate results tailored to your needs.
