

What is Vector Space Representation?
Vector Space Representation is a method of representing text data, such as documents, sentences, or words, in a mathematical format, where each text element is converted into a vector. A vector is an array of numbers that captures the characteristics or features of the text in a multi-dimensional space. It is widely used in Information Retrieval (IR), Natural Language Processing (NLP), and Machine Learning to compare, categorize, or retrieve text data efficiently. What is Vector Space Representation? In this article, we will explore how Vector Space Representation works, its importance in text analysis, and its applications in enhancing data retrieval and machine learning models.
Key Concepts Behind Vector Space Representation
In Vector Space Representation, each dimension corresponds to a unique term or feature in the dataset, and the values in each dimension represent the importance, frequency, or relevance of that term in the context of the text. The key components are as follows:
1. Terms (or Features)
The dimensions of the vector space are created based on the unique terms or words found in the text data. In a collection of documents, the terms or features define the vector space.
2. Document Representation
Once the terms are identified, each document is represented as a vector, with each element corresponding to a specific term’s importance within the document. Various weighting schemes, such as Term Frequency (TF), Inverse Document Frequency (IDF), or the combination of both (TF-IDF), can determine these values.
3. Multidimensional Space
In vector space representation, terms form a high-dimensional space, where each document is mapped as a point. The proximity between document vectors indicates the similarity between the corresponding documents.
How Does Vector Space Representation Work?
The process works as follows:
1. Preprocessing the Text
Text documents are preprocessed by removing stop words, stemming, and tokenizing the text into terms.
2. Term Selection
A list of unique terms (vocabulary) is created across all documents, and each term is assigned a dimension in the vector space.
3. Vector Creation
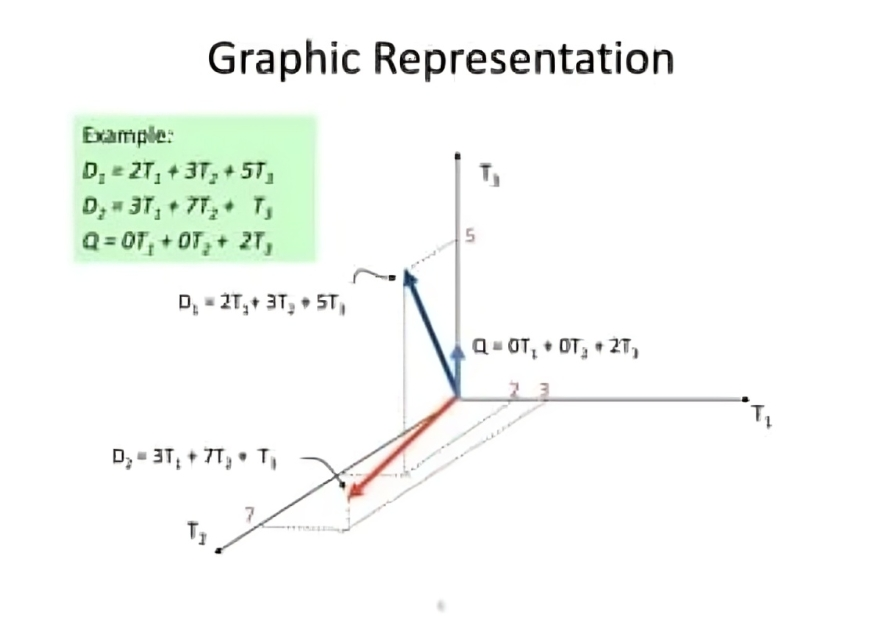
Each document is represented as a vector where each element corresponds to the frequency or weight of a term in the document. For example, if the vocabulary contains "apple", "banana", and "fruit," and Document 1 contains "apple" once, the vector for Document 1 could be [1, 0, 0]. If Document 2 contains "banana" and "fruit", its vector could be [0, 1, 1].
4. Document Comparison
Once all documents are represented as vectors, they can be compared using similarity metrics like Cosine Similarity or Euclidean Distance. Documents that are closer in the vector space are considered more similar.
Advantages of Vector Space Representation
Vector space representation offers several benefits:
- Quantifiable Representation: Text, which is inherently unstructured, is converted into a structured, quantifiable format for machine processing.
- Scalability: Large datasets can be efficiently processed by converting text into vectors.
- Flexibility: The model can accommodate new terms or features as the dataset grows.
Applications of Vector Space Representation
Vector space representation is applied in various fields:
1. Information Retrieval (Search Engines)
Search engines use vector space representation to rank and retrieve documents based on similarity to user queries.
2. Text Classification
It is used to categorize documents into predefined categories, such as spam detection or sentiment analysis.
3. Recommendation Systems
By representing user preferences and product descriptions as vectors, recommendation engines can suggest similar items.
4. Clustering and Topic Modeling
Vector space representation helps in clustering documents based on content similarity, grouping them into meaningful topics.
Limitations of Vector Space Representation
While powerful, vector space representation has some limitations:
- High Dimensionality: The vector space can become large, leading to computational inefficiency.
- Sparsity: Many vectors contain zero values, leading to sparse matrices that are inefficient for storage and computation.
- Lack of Semantic Understanding: Basic models do not capture semantic meaning, such as the similarity between "cat" and "kitten".
Enhancements to Vector Space Representation
Several techniques can enhance vector space models:
1. Latent Semantic Analysis (LSA)
LSA reduces the dimensionality of the vector space and uncovers hidden relationships between terms, improving accuracy.
2. Word Embeddings
Modern NLP techniques like Word2Vec or GloVe represent words as dense vectors, capturing semantic similarity and overcoming traditional model limitations.
Conclusion
Vector Space Representation is a key technique in Information Retrieval and NLP, transforming text data into a mathematical format that enables efficient analysis, comparison, and retrieval. It plays a significant role in improving search engines, recommendation systems, and other applications. At Flax Infotech, we leverage advanced vector space models along with cutting-edge technologies to develop intelligent solutions that help businesses optimize content retrieval and deliver personalized user experiences.
Contact us today to discuss how we can apply vector space techniques to your organization’s needs and help you get the most out of your data.
